Article
Video


Generative AI is everywhere, and you might be feeling the pressure from your colleagues or managers to explore how to incorporate Generative AI into your role or business. I’ve been seeing a lot of speculation about ChatGPT’s capabilities and what it can and cannot do. As a research scientist with years of experience in academic and industrial research with large language models, I wanted to dig into some of these notions:
First, ChatGPT is not a product, it’s an engine – and a really good one. However, a valuable solution still needs more in order to make a difference and drive business value in almost every case. This includes the UX (UI, latency, runtime constraints) and critical ML capabilities like data collection, data processing and selection, continuous training frameworks, optimizing models for outcomes (beyond next word prediction) and deployment (measurement, A/B tests, telemetry).
Second, while GPT does amazing things like write poetry, pass medical exams or write code (just to name a few), in CX we need solutions that solve specific problems like improving automated dispositioning or real-time agent augmentation. GPT models can be impressive, but when it comes to user experience and business outcomes, Vertical generative AI models that are trained on human data in a dynamic environment specifically for the task at hand typically outperform larger generic algorithms. In ASAPP’s case, this means solving customer experience pain points and building technology to make agents more productive.
Lastly, while we don’t use ChatGPT at ASAPP, we do train large language models and have deployed them for years. We don’t pre-train them on the web, but we do pre-train them on our customer data, which is quite sizable. From there, we then train them to solve specific tasks optimizing the model for specific KPIs and business outcomes we care about and need to solve for our customers — not just general AI. This includes purpose-built vertical AI technology for contact centers and CX. Vertical AI allows enterprises to transform by automating workflows, multiplying agent productivity and generating customer intelligence to provide optimal CX.
Interested in learning more about ChatGPT or how large language models might benefit your business? Drop us a line.
The mission of Solution Design at ASAPP is to help companies identify areas of massive opportunity when it comes to optimizing their contact centers and digital customer experiences. At the highest level, we aim to help our customers provide an extremely personalized and proactive experience at a very low cost by leveraging machine learning and AI. While we’ve seen many different cost saving and personalization strategies when it comes to the contact center, the most common by far is as follows:
It’s a strategy that many Fortune 500 companies were convinced would revolutionize the customer experience and bring about significant cost savings. Excited by the promises of chatbot and IVR companies who said they could automate 80% of interactions within a year—which they assumed would reduce the need for agents to handle routine tasks– companies spent millions of dollars on these technologies.
While some are seeing high containment numbers put forth in business cases, the expected savings haven’t materialized—as evidenced by how much these companies continue to spend on customer service year after year. Furthermore, customers are frustrated by this strategy—with most people (myself included) asking repeatedly for an agent once they interact with an IVR or bot. The fact is, people are calling in about more complex topics, which require knowledgeable and empathetic people on the other end of the line.

We live in a new era where the companies who can provide extremely efficient and personalized interactions at a lower cost than their competitors are winning out.
Austin Meyer
It’s not surprising that in 2019, executive mentions of chatbots in earnings calls dropped dramatically and chatbot companies struggled to get past seed rounds of investment (cite). These programs cost millions of dollars in software and tooling, and double or triple that for the labor involved with building, maintaining, measuring, and updating logic flows. Beyond NOT increasing contact center efficiency, chatbot technology has reduced customer satisfaction, impeded sales conversion, and has caused the market to missassociate AI with automate everything or nothing.
We live in a new era where the companies who can provide extremely efficient and personalized interactions at a lower cost than their competitors are winning out.
There has been a retreat from using bot automation to avoid customer contact. Instead, leading companies are using ML and AI to improve digital customer experiences while simultaneously helping agents become more efficient. Furthermore, by connecting the cross channel experiences and using machine learning across them, conversational data is much more complete and more valuable to the business.
Compared to the earlier strategy, where there were distinct walls between self service, automation and agents, this new strategy looks far more blended. Notice that automation doesn’t stand alone—instead, it’s integrated with the customer experience AND agent workflows. Machine learning provides efficiency gains by enabling automation whenever appropriate, leading to faster resolution regardless of channel.
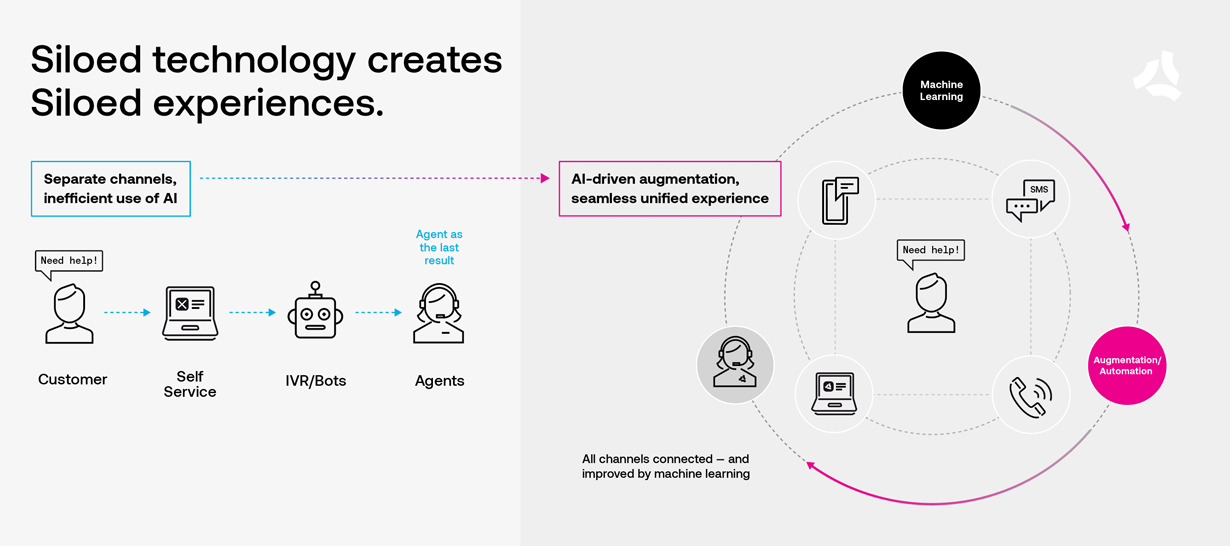
At ASAPP, we use AI-driven agent augmentation and automation to improve customer experience and increase contact center efficiency. The results have been transformative—saving our customers millions of dollars in opex, generating millions in additional revenue while dramatically improving CSAT/NPS and digital engagement. If you want to learn more about our research, results, or strategy reach out to me at solutions@asapp.com.
For decades, one of the biggest consumer complaints has been that companies don’t really know them. Businesses may use segmentation for marketing, yet for inbound customer service, even this level of personalization is nearly non-existent. Now the race is on—because personalized service experiences are quickly becoming a brand differentiator.
When customers reach out to solve a problem, they want to feel reassured and valued. But too often, they’re treated like a number and end up more frustrated. Even if they get good service on one call, the next time they contact customer service it’s basically starting at ground zero because the next agent doesn’t know them.
As more digital customer service channels have emerged, consumers have gained more choices and digital convenience. But that creates a new challenge: people often use different channels at different times, switching between calls, web chat, digital messaging, and social media. And because those channels are often siloed, customers may get a very impersonal and disjointed experience.
The new demand for personalization requires something significantly better. Consumers now expect seamless experiences across their relationship with a company—and without it, brands will struggle to earn repeat business, let alone loyalty. In fact, nearly 60% of consumers say personalized engagement based on past interactions is very important to winning their business.
Knowing your customers means providing seamless continuity wherever they engage with your brand. Typically, the experience is fragmented, and consumers have a right to expect better. They provide a considerable amount of data through various channel interactions, and 83% of consumers are willing to share that data to receive more personalized experiences.
When a company barely knows them from one engagement to the next, how do you think that affects their trust in the brand?
It’s no surprise that 89% of digital businesses are investing in personalization. Cutting edge technologies are eliminating the friction and fragmentation of multi-channel journeys, by meeting customers with full context however they make contact. With a unified, AI-powered platform for customer experience, companies can seamlessly integrate voice and digital capabilities—and ensure customers are greeted every time with an understanding of their history with the company, where they’ve been and what happened in previous interactions It gives customers greater flexibility and ease for engaging using their preferred channels, which can dramatically improve satisfaction ratings and NPS scores.
Another powerful benefit of multi-channel integration is that it enables contact centers to think in terms of conversations instead of cases. A unified platform weaves together voice and digital messages into a cohesive thread for a given customer. Any agent can easily step in and join that conversation, having all the right knowledge about the situation and visibility into previous interactions. That continuity enables agents to provide more personalized attention that helps ensure the customer feels known and valued.

Customer service needs to be about conversations, not cases. Creating intelligent, personalized continuity across all engagement channels shows customers you know and value them—and that’s the great CX that wins loyalty.
Michael Lawder
Tapping into a wealth of customer data from many different channels, companies can take customer experience to the next level. Using AI and machine learning, you can build more comprehensive customer histories and serve up predictive, personalized action plans specifically relevant for each customer.
I’m talking about gaining a holistic picture of when, why, and how each customer has engaged over their lifecycle with your company. That opens up significant opportunities, such as:
Most consumers now expect companies to know them better and see that reflected in their communications. And the demand for personally relevant experiences isn’t just about marketing—it’s across the journey, including customer service. That’s why ASAPP technology is so compelling.
Support interactions are often the defining moments that dictate how people feel about a brand. The more you can personalize those customer service moments, the more you will earn loyalty, and even word-of-mouth referrals as your happy customers become brand advocates.
ASAPP researchers have spent the past 8+ years pushing the limits of machine learning to provide contact center agents with content suggestions that are astonishingly timely, relevant, and helpful. While these technological advancements are ground-breaking, they’re only part of the success of AutoCompose. Knowing what the agent should say or do next is only half the battle. Getting the agent to actually notice, trust, and engage with the content is an entirely different challenge.
While it may not be immediately noticeable to you as a customer, contact center agents often navigate a head-exploding mash-up of noisy applications and confusing CRMs when working towards a resolution. Beyond that, they juggle well-meaning protocols and policies that are intended to ensure quality and standardize workflows, but instead quickly become overwhelming and ineffective—if not counter-productive.
The ASAPP Design team took notice of this ever-growing competition for attention and sought to turn down the noise when designing AutoCompose.
Instead of getting bigger and louder in our guidance, we focused on a flexible and intuitive UI that gives agents the right amount of support at exactly the right time—all without being disruptive to their natural workflow.
Min Kim
We had several user experience imperatives when iterating on the AutoCompose UI design.
Knowing where to showcase suggestions isn’t obvious. We experimented with several underperforming placements until landing on the effective solution: wedging the UI directly in the line of sight between the composer input and the chat log. The design was minimalist, keeping visual noise to a minimum and focusing on contrast and legibility.
The value of AutoCompose stems from recognition rather than recall, which takes advantage of the human brain’s ability to digest recent and contextual information at a time. Instead of memorizing an infinite number of templates and commands, AutoCompose includes suggestions in multiple locations where an agent can recognize and choose. When the agent is in the middle of drafting a sentence, Phrase Auto-Complete prompts the suggested full sentence inline within the text input. As an agent types words and phrases, AutoSuggest gives the most relevant suggestions at the given context, located between the chat log and composer, so that the agent can stay informed about the chat context. By placing suggestions where they need it, agents can immediately recognize and utilize them with maximum efficiency.
In UI design, there is often a fine line between too much and too little. We experienced this when evaluating the threshold for how many suggestions to display. AutoSuggest currently displays up to three suggestions that update in real-time as an agent types. We’ve been intentional about capping suggestions to a maximum of three, and do our best effort to make them relevant. The model only shows confident, quality-ensured suggestions above a set threshold. With this, the UI shows the right amount of suggestions that optimize for the cognitive load that agents can handle at a time.

Another critical component to the design is latency. To fit within an agent’s natural workflow, the suggestions must update within a fraction of a second—or risk the agent ignoring the suggestions altogether.
Specifically, a latency of less than 100ms ensures the agent feels a sense of direct manipulation associated with every keystroke. Beyond that, the updating of suggestions can fall behind the pace of conversation, making the experience painfully disjointed.
In contact centers, when agents encounter complex issues, they may choose to resolve them differently depending on their tenure and experience. In these scenarios, we may not have the right answer, so we instantly shift our UX priorities to make it easy for the agents to find what they’re looking for.


We focused on integrating search and other browsing (and use of shortcuts), all in a compact, but extremely dynamic UI. Experienced agents may need to pull effective responses that they built on their own. Meanwhile, novice agents need more handholding to pull from company-provided response suggestions, also known as global responses. To accommodate both, we experimented with ways to introduce shortcuts like a drawer search inline within the text field, and a global response search that is prompted on top of AutoSuggest. AutoCompose now accommodates these long tail use cases with our dynamic, contextual UI approach.
What might seem like a simple UI is actually packed with details and nuanced interactions to maximize agent productivity. With subtle and intentional design decisions, we give the right amount of support to agents at the right time.
At ASAPP we develop AI models to improve agent performance. Many of these models directly assist agents by automating parts of their workflow. For example, the automated responses generated by AutoCompose suggest to an agent what to say at a given point during a customer conversation. Agents often use our suggestions by clicking and sending them.
While usage of the suggestions is a great indicator of whether the agents like the features, we’re even more interested in the impact the automation has on performance metrics like agent handle time, concurrency, and throughput. These metrics are ultimately how we measure agent performance when evaluating the impact of a product like AutoCompose, but these metrics can be affected by things beyond AutoCompose usage, like changes in customer intents or poorly-planned workforce management.
To isolate the impact of AutoCompose usage on agent efficiency, we prefer to measure the specific performance gains from each individual usage of AutoCompose. We do this by measuring the impact of automated responses on agent response time, because response time is more invariant to intent shifts and organizational effects than handle time, concurrency and throughput.
By doing this, we can further analyze:
Altogether, this enables us to be data-driven about how we improve models and develop new features to have maximum impact.
When we train AI models to automate responses for agents, the models look for patterns in the data that can predict what to say next based on past conversation language. So the easiest things for models to learn well are the types of messages that occur often and without much variation across different types of conversations, e.g. greetings and closings. Agents typically greet and end a conversation with a customer the same way, perhaps with some specificity based on the customer’s intent.

Most AI-driven automated response products will correctly suggest greeting and closing messages at the correct time in the conversation. This typically accounts for the first 10-20% of automated response usage rates. But when we evaluate the impact of automating those types of messages, we see that it’s minimal.
To understand this, let’s look at how we measure impact. We compare agents’ response times when using automated responses against their response times when not using automated responses. The difference in time is the impact—it’s the time savings we can credit to the automation.
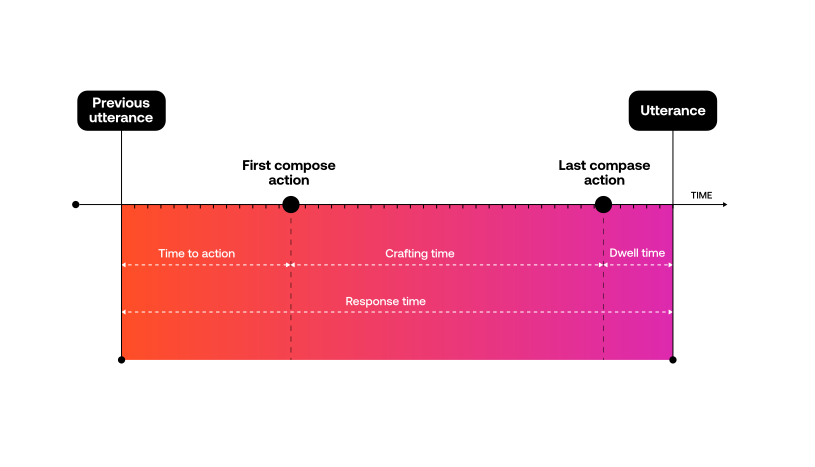
Without automation, agents are not manually typing greeting and closing messages for every conversation. Rather they’re copying and pasting from notepad or word documents containing their favorite messages. Agents are effective at this because they do it several times per conversation. They know exactly where their favorite messages are located, and they can quickly copy and paste them into their chat window. Each greeting or closing message might take an agent 2 seconds. When we automate those types of messages, all we are actually automating is the 2 second copy/paste. So when we see automation rates of 10-20%, we are likely only seeing a minimal impact on agent performance.
If automating the beginnings and endings of conversations is not that impactful, what is?

Automating the middle of the conversation is where response times are naturally slowest and where automation can yield the most agent performance impact.
The agent may not know exactly what to say next, requiring time to think or look up the right answers. It’s unlikely that the agent has a script readily available for copying or pasting. If they do, they are not nearly as efficient as they are with their frequently used greetings and closings.
Where it was easy for AI models to learn the beginnings and endings of conversations, because they most often occur the same way, the exact opposite is true of the middle parts of conversations. Often, this is where the most diversity in dialog occurs. Agents handle a variety of customer problems, and they solve them in a variety of ways. This results in extremely varied language throughout the middle parts of conversations, making it hard for AI models to predict what to say at the right time.

ASAPP’s research delivers the biggest improvements
Whole interaction models are exactly what the research team at ASAPP specializes in developing. And it’s the reason that AutoCompose is so effective. If we look at AutoCompose usage rates throughout a conversation, we see that while there is a higher usage at the beginnings and endings of conversations, AutoCompose still automates over half of agent responses in between.
The low response times in the middle of conversations are where we see the biggest improvements in agent response time. It’s also where the biggest opportunities for improvements are realized.
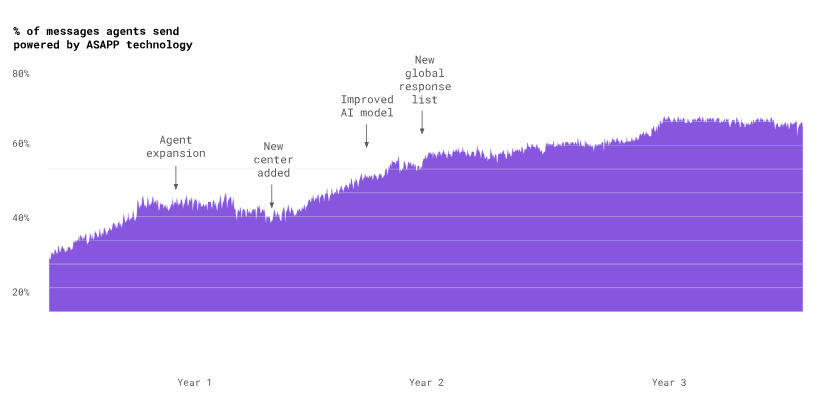
ASAPP’s current automated response rate is about 75%. It has taken a lot of model improvements, new features, and user-tested designs to get there. But now agents effectively use our automated responses to reduce handle times by 16%, enabling an additional 15% of agent concurrency, for a combined improvement in throughput of 35%. The AI model continues to get better with use, improving suggestions, and becoming more useful to agents and customers.
Customer care leaders tasked with improving customer satisfaction while also reducing cost often find it challenging to know where to begin. It’s hard to know what types of problems are ideal for self-serve, where the biggest bottlenecks exist, what workflows could be streamlined, and how to provide both the right training and targeted feedback to a large population of agents.
We talk with stakeholders from many companies who are charged with revamping the tools agents have at their disposal to improve agent effectiveness and decrease negative outcomes like call-backs and handle time.
Some of the first questions they ask are:
These questions require an understanding of both the tools that agents use and the entire landscape of customer problems. This is the first blog in a series that details how an ASAPP AI Service, JourneyInsight, ties together what agents are saying and doing with key outcomes to answer these questions.

Using JourneyInsight, customer care leaders can make data-driven, impactful improvements to agent processes and agent training.
Most customers start with our diagnostic reports to identify problem areas and help them prioritize improvements. They then use our more detailed reports that tie agent behavior with outcomes and compare performance across agent groups to drive impactful changes.
These Diagnostic reports provide visibility and context behind KPIs that leaders have not had before.
Our Time-on-Tools report captures how much time agents spend on each of their tools for each problem type or intent. This enables a user to:
With this report, it’s easy to see the problem types where agents are still relying on legacy tools or how the 20% least tenured agents spend 30% more time on the payments page than their colleagues do for a billing related question.
Our Agent Effort report captures the intensity of the average issue for each problem type or intent, This enables a user to:
With this report, it’s easy to identify which problem types require the most effort to resolve, how the best agents interact with their tools, and how each agent stacks up against the best agents.
These examples illustrate some of the ways our customers have used these reports to answer key questions.
When looking for intents to address with self-serve capabilities, it is critical to know how much volume could be reduced and the cost of implementation. The cost can be informed by how complex the problem-solving workflows are and which systems will need to be integrated with.
Our diagnostic reports for one customer for a particular intent showed that:
All of these data points indicate that this intent is simple, consistent, and requires relaying information from one existing system to a customer. This makes it a good candidate to build into a self-serve virtual agent flow.
Our more detailed process discovery reports can identify multiple workflows per intent and outline each workflow. They also provide additional details and statistics needed to determine whether the workflow is ideal for automation.
Correct resource usage is generally determined by the context of the problem and the type or level of agent using the resource.
Our diagnostic reports for one customer for a particular intent showed that:
These data points suggest that this intent is harder to solve than expected and that resources need to be updated to provide agents with the answers they need. It is also possible that agents were not aware of the resources that have been designed to help solve that problem.
We followed up to take a deeper look with our more detailed outcome drivers report. It showed that when agents use the knowledge base article written for that intent, callback rates are lower. This indicates that the article likely does, in fact, help agents resolve the issue.
In subsequent posts, we’ll describe how we drive more value using predictive models and sequence mining to help identify root causes of negative outcomes and where newer agents are deviating from more tenured agents.
Progress on speech processing has benefited from shared datasets and benchmarks. Historically, these have focused on automatic speech recognition (ASR), speaker identification, or other lower-level tasks. However, “higher-level” spoken language understanding (SLU) tasks have received less attention and resources in the speech community. There are numerous tasks at varying linguistic levels that have been benchmarked extensively for text input by the natural language processing (NLP) community – named entity recognition, parsing, sentiment analysis, entailment, summarization, and so on – but they have not been as thoroughly addressed for speech input.
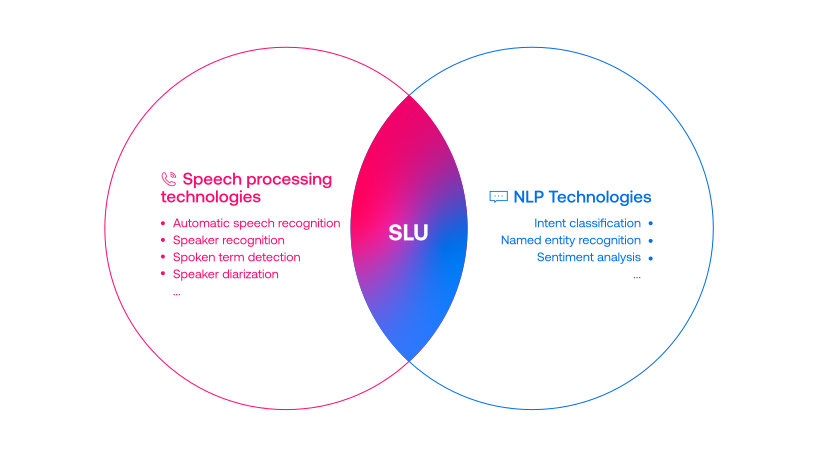
Consequently, SLU is at the intersection of speech and NLP fields but was not addressed seriously from either side. We think that the biggest reason for this disconnect is due to a lack of an appropriate benchmark dataset. This lack makes performance comparisons very difficult and raises the barriers of entry into this field. A high quality benchmark would allow both the speech and NLP community to address open research questions about SLU—such as which tasks can be addressed well by pipeline ASR+NLP approaches, and which applications benefit from having end to end or joint modeling. And, for the latter kind of tasks, how to best extract the needed speech information.

For conversational AI to advance, the broader scientific community must be able to work together and explore with easily accessible state-of-the-art baselines for fair performance comparisons.
We believe that for conversational AI to advance, the broader scientific community must be able to work together and explore with easily accessible state-of-the-art baselines for fair performance comparisons. A present lack of benchmarks of this kind is our main motivation in establishing the SLUE benchmark and its suite.
We are launching the first benchmark which considers ASR, NER, and SLU with a particular emphasis on low-resource SLU. For this benchmark, we contribute the following:
SLUE covers 2 SLU tasks (NER and SA) + ASR tasks. All evaluation in this benchmark starts with the speech as input whether it is a pipeline approach (ASR+NLP model) or end-to-end model that predicts results directly from speech.
The provided SLUE benchmark suite covers for downloading dataset, training state-of-the-art baselines and evaluation with high-quality annotation. In the website, we provide the online leaderboard to follow the up-to-date performance and we strongly believe that the SLUE benchmark makes SLU tasks much more easily accessible and researchers can focus on problem-solving.
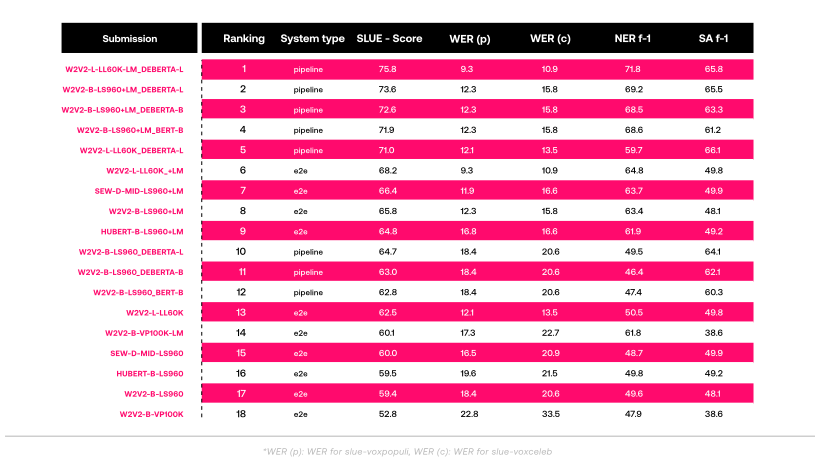
Current leaderboard of the SLUE benchmark
Recent SLU-related benchmarks have been proposed with similar motivations to SLUE. However, those benchmarks cannot perform as comprehensively as SLUE due to the following reasons:
SLUE provides a comprehensive comparison between models without those shortcomings. An expected contribution to the SLUE benchmark would
Motivated by the growing interest in SLU tasks and recent progress on pre-trained representations, we have proposed a new benchmark suite consisting of newly annotated fine-tuning and evaluation sets, and have provided annotations and baselines for new NER, sentiment, and ASR evaluations. For the initial study of the SLUE benchmark, we evaluated numerous baseline systems using current state-of-the-art speech and NLP models.
This work is open to all researchers in the multidisciplinary community. We welcome similar research efforts focused on low-resource SLU, so we can continue to expand this benchmark suite with more tests and data. To contribute or expand on our open-source dataset, please email or get in touch with us at sshon@asapp.com.